Auphonic is now available from the command line:
The Auphonic CLI lets you
process, manage, and automate audio productions
without leaving the terminal.
It's a free, single binary with no dependencies —
just download it, authenticate, and start processing.
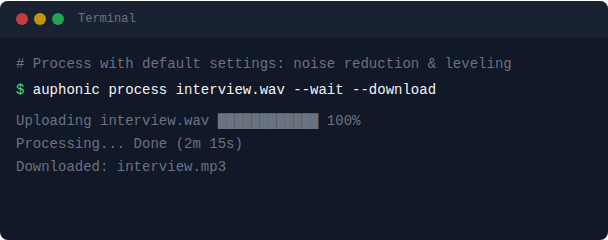
Everything you know from Auphonic is available: Noise Reduction, Loudness Normalization, Speech Recognition, Multitrack Processing, Presets, and publishing to External Services. All from a single command.
Use Cases
Whether you're producing a single episode or processing thousands of files, the CLI fits into a wide range of workflows:
File-based workflows: If you're a broadcaster, podcaster, ...





